
We’ve created our own (very) simple ORM for saving data in Neo4J. Performance was not relevant until loading a weekly batch took about 8 days. After some tweaks we manage to load the data in just over one day. (29 hours) Here is how we tuned our code. Your milage may vary.
For those unfamiliar with Neo4J: it’s a graph database that uses cypher to manipulate data. I’ve written about it here.

Image by Gordon Johnson from Pixabay.com
The ORM is hosted in a aspnet webapi. In the json we receive the tree is already build and there is a single rootnode. This rootnode is saved with all related nodes. Then the relations between the rootnode and the nodes are saved. By making the calls recursive with the related nodes as rootnode the complete tree of nodes is saved this way. Again, this is a (very) simple ORM.
By logging the time needed for each recursion we found a type of node with many relations. Think thousands of relations from that one node to (leaf)nodes. That was our bottleneck. We managed to handle the node differently based on the type of the node. A special function would be called to handle the great amount of relations, but how?
Looking for the type of node in all loads we performed we noticed a relation between the number of leafnodes and the time it took to save. This relation was not linear. We put the numbers in a spreadsheet and created a plot. The optimum between number of nodes in a transaction and load-time was around 10.000. So we created a loop in the special function that would create a new transaction every 10.000 nodes.
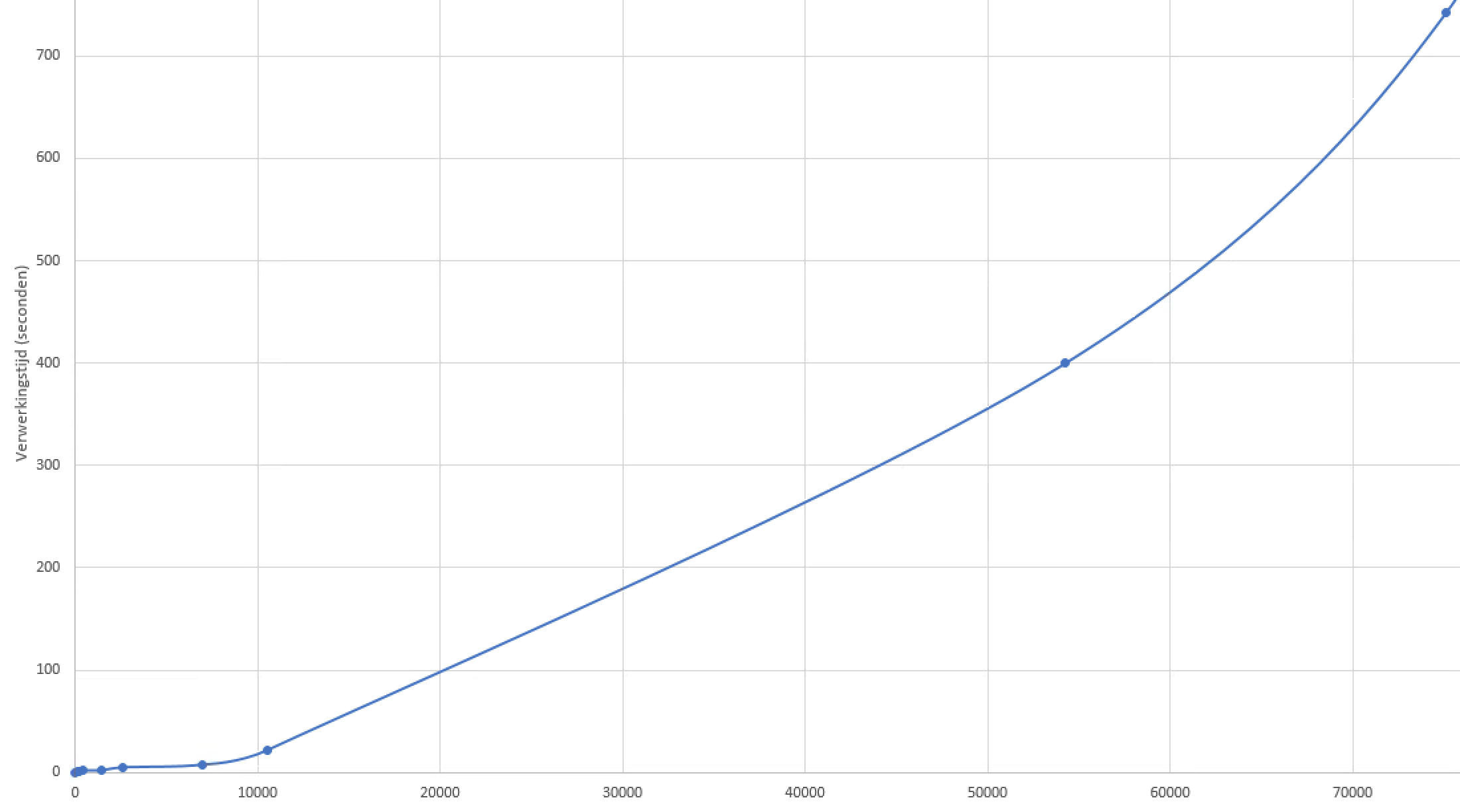
Thanks to the logging we identified this tweak. There may be more optimisations, but this brought us back on track. Simple 20-80 rule applied ![]()
